Niels Thykier: Providing online reference documentation for debputy
I do not think seasoned Debian contributors quite appreciate how much knowledge we
have picked up and internalized. As an example, when I need to look up
documentation for debhelper, I generally know which manpage to look in. I suspect
most long time contributors would be able to a similar thing (maybe down 2-3
manpages). But new contributors does not have the luxury of years of experience.
This problem is by no means unique to debhelper.
One thing that debhelper does very well, is that it is hard for users to tell
where a addon "starts" and debhelper "ends". It is clear you use addons, but
the transition in and out of third party provided tools is generally smooth. This
is a sign that things "just work(tm)".
Except when it comes to documentation. Here, debhelper's static documentation
does not include documentation for third party tooling. If you think from a
debhelper maintainer's perspective, this seems obvious. Embedding documentation
for all the third-party code would be very hard work, a layer-violation, etc.. But
from a user perspective, we should not have to care "who" provides "what". As as
user, I want to understand how this works and the more hoops I have to jump through
to get that understanding, the more frustrated I will be with the toolstack.
With this, I came to the conclusion that the best way to help users and solve the
problem of finding the documentation was to provide "online documentation". It
should be possible to ask debputy, "What attributes can I use in
install-man?" or "What does path-metadata do?". Additionally, the lookup
should work the same no matter if debputy provided the feature or some
third-party plugin did. In the future, perhaps also other types of documentation
such as tutorials or how-to guides.
Below, I have some tentative results of my work so far. There are some
improvements to be done. Notably, the commands for these documentation features
are still treated a "plugin" subcommand features and should probably have its own
top level "ask-me-anything" subcommand in the future.
Automatic discard rules
Since the introduction of install rules, debputy has included an automatic
filter mechanism that prunes out unwanted content. In 0.1.9, these filters
have been named "Automatic discard rules" and you can now ask debputy to
list them.
For these rules, the provider can both provide a description but also an example
of their usage.
The example is a live example. That is, the provider will provide debputy
with a scenario and the expected outcome of that scenario. Here is the concrete
code in debputy that registers this example:
When showing the example, debputy will validate the example matches what the plugin
provider intended. Lets say I was to introduce a bug in the code, so that the discard rule
no longer worked. Then debputy would start to show the following:
Obviously, it would be better if this validation could be added directly as a plugin test,
so the CI pipeline would catch it. That is one my personal TODO list. :)
One final remark about automatic discard rules before moving on. In 0.1.9, debputy will also
list any path automatically discarded by one of these rules in the build output to make sure
that the automatic discard rule feature is more discoverable.
$ debputy plugin list automatic-discard-rules
+-----------------------+-------------+
Name Provided By
+-----------------------+-------------+
python-cache-files debputy
la-files debputy
backup-files debputy
version-control-paths debputy
gnu-info-dir-file debputy
debian-dir debputy
doxygen-cruft-files debputy
+-----------------------+-------------+
$ debputy plugin show automatic-discard-rules la-files
Automatic Discard Rule: la-files
================================
Documentation: Discards any .la files beneath /usr/lib
Example
-------
/usr/lib/libfoo.la << Discarded (directly by the rule)
/usr/lib/libfoo.so.1.0.0
api.automatic_discard_rule(
"la-files",
_debputy_prune_la_files,
rule_reference_documentation="Discards any .la files beneath /usr/lib",
examples=automatic_discard_rule_example(
"usr/lib/libfoo.la",
("usr/lib/libfoo.so.1.0.0", False),
),
)
# Output if the code or example is broken
$ debputy plugin show automatic-discard-rules la-files
[...]
Automatic Discard Rule: la-files
================================
Documentation: Discards any .la files beneath /usr/lib
Example
-------
/usr/lib/libfoo.la !! INCONSISTENT (code: keep, example: discard)
/usr/lib/libfoo.so.1.0.0
debputy: warning: The example was inconsistent. Please file a bug against the plugin debputy
Plugable manifest rules like the install rule
In the manifest, there are several places where rules can be provided by plugins. To make
life easier for users, debputy can now since 0.1.8 list all provided rules:
(Output trimmed a bit for space reasons)
And you can then ask debputy to describe any of these rules:
(Output trimmed a bit for space reasons)
All the attributes and restrictions are auto-computed by debputy from information
provided by the plugin. The associated documentation for each attribute is supplied
by the plugin itself, The debputy API validates that all attributes are covered
and the documentation does not describe non-existing fields. This ensures that you as
a plugin provider never forget to document new attributes when you add them later.
The debputy API for manifest rules are not quite stable yet. So currently only
debputy provides rules here. However, it is my intention to lift that restriction
in the future.
I got the idea of supporting online validated examples when I was building this feature.
However, sadly, I have not gotten around to supporting it yet.
$ debputy plugin list plugable-manifest-rules
+-------------------------------+------------------------------+-------------+
Rule Name Rule Type Provided By
+-------------------------------+------------------------------+-------------+
install InstallRule debputy
install-docs InstallRule debputy
install-examples InstallRule debputy
install-doc InstallRule debputy
install-example InstallRule debputy
install-man InstallRule debputy
discard InstallRule debputy
move TransformationRule debputy
remove TransformationRule debputy
[...] [...] [...]
remove DpkgMaintscriptHelperCommand debputy
rename DpkgMaintscriptHelperCommand debputy
cross-compiling ManifestCondition debputy
can-execute-compiled-binaries ManifestCondition debputy
run-build-time-tests ManifestCondition debputy
[...] [...] [...]
+-------------------------------+------------------------------+-------------+
$ debputy plugin show plugable-manifest-rules install
Generic install ( install )
===========================
The generic install rule can be used to install arbitrary paths into packages
and is *similar* to how dh_install from debhelper works. It is a two "primary" uses.
1) The classic "install into directory" similar to the standard dh_install
2) The "install as" similar to dh-exec 's foo => bar feature.
Attributes:
- source (conditional): string
sources (conditional): List of string
A path match ( source ) or a list of path matches ( sources ) defining the
source path(s) to be installed. [...]
- dest-dir (optional): string
A path defining the destination *directory*. [...]
- into (optional): string or a list of string
A path defining the destination *directory*. [...]
- as (optional): string
A path defining the path to install the source as. [...]
- when (optional): manifest condition (string or mapping of string)
A condition as defined in [Conditional rules](https://salsa.debian.org/debian/debputy/-/blob/main/MANIFEST-FORMAT.md#Conditional rules).
This rule enforces the following restrictions:
- The rule must use exactly one of: source , sources
- The attribute as cannot be used with any of: dest-dir , sources
[...]
Manifest variables like PACKAGE
I also added a similar documentation feature for manifest variables such as
PACKAGE . When I implemented this, I realized listing all manifest variables
by default would probably be counter productive to new users. As an example, if you
list all variables by default it would include DEB_HOST_MULTIARCH (the most common
case) side-by-side with the the much less used DEB_BUILD_MULTIARCH and the even
lessor used DEB_TARGET_MULTIARCH variable. Having them side-by-side implies they
are of equal importance, which they are not. As an example, the ballpark number of
unique packages for which DEB_TARGET_MULTIARCH is useful can be counted on two
hands (and maybe two feet if you consider gcc-X distinct from gcc-Y).
This is one of the cases, where experience makes us blind. Many of us probably have the
"show me everything and I will find what I need" mentality. But that requires experience
to be able to pull that off - especially if all alternatives are presented as equals.
The cross-building terminology has proven to notoriously match poorly to people's
expectation.
Therefore, I took a deliberate choice to reduce the list of shown variables by default
and in the output explicitly list what filters were active. In the current version
of debputy (0.1.9), the listing of manifest-variables look something like this:
I will probably tweak the concrete listing in the future. Personally, I am considering to provide
short-hands variables for some of the DEB_HOST_* variables and then hide the DEB_HOST_*
group from the default view as well. Maybe something like ARCH and MULTIARCH, which
would default to their DEB_HOST_* counter part. This variable could then have extended
documentation that high lights DEB_HOST_<X> as its source and imply that there are special
cases for cross-building where you might need DEB_BUILD_<X> or DEB_TARGET_<X>.
Speaking of variable documentation, you can also lookup the documentation for a given
manifest variable:
This was my update on online reference documentation for debputy. I hope you found it
useful. :)
$ debputy plugin list manifest-variables
+----------------------------------+----------------------------------------+------+-------------+
Variable (use via: NAME ) Value Flag Provided by
+----------------------------------+----------------------------------------+------+-------------+
DEB_HOST_ARCH amd64 debputy
[... other DEB_HOST_* vars ...] [...] debputy
DEB_HOST_MULTIARCH x86_64-linux-gnu debputy
DEB_SOURCE debputy debputy
DEB_VERSION 0.1.8 debputy
DEB_VERSION_EPOCH_UPSTREAM 0.1.8 debputy
DEB_VERSION_UPSTREAM 0.1.8 debputy
DEB_VERSION_UPSTREAM_REVISION 0.1.8 debputy
PACKAGE <package-name> debputy
path:BASH_COMPLETION_DIR /usr/share/bash-completion/completions debputy
+----------------------------------+----------------------------------------+------+-------------+
+-----------------------+--------+-------------------------------------------------------+
Variable type Value Option
+-----------------------+--------+-------------------------------------------------------+
Token variables hidden --show-token-variables OR --show-all-variables
Special use variables hidden --show-special-case-variables OR --show-all-variables
+-----------------------+--------+-------------------------------------------------------+
$ debputy plugin show manifest-variables path:BASH_COMPLETION_DIR
Variable: path:BASH_COMPLETION_DIR
==================================
Documentation: Directory to install bash completions into
Resolved: /usr/share/bash-completion/completions
Plugin: debputy
Thanks
On a closing note, I would like to thanks Jochen Sprickerhof, Andres Salomon, Paul Gevers
for their recent contributions to debputy. Jochen and Paul provided a number of real
world cases where debputy would crash or not work, which have now been fixed. Andres
and Paul also provided corrections to the documentation.

 I've finally landed a patch/feature for HLedger I've been working on-and-off
(mostly off) since around March.
HLedger has a powerful CSV importer which you configure with a set of rules.
Rules consist of conditional matchers (does field X in this CSV row match
this regular expression?) and field assignments (set the resulting
transaction's account to Y).
motivating problem 1
Here's an example of one of my rules for handling credit card repayments. This
rule is applied when I import a CSV for my current account, which pays the
credit card:
I've finally landed a patch/feature for HLedger I've been working on-and-off
(mostly off) since around March.
HLedger has a powerful CSV importer which you configure with a set of rules.
Rules consist of conditional matchers (does field X in this CSV row match
this regular expression?) and field assignments (set the resulting
transaction's account to Y).
motivating problem 1
Here's an example of one of my rules for handling credit card repayments. This
rule is applied when I import a CSV for my current account, which pays the
credit card:

 Check it out
Check it out 


 TL;DR: Squash your PRs with one click at
TL;DR: Squash your PRs with one click at 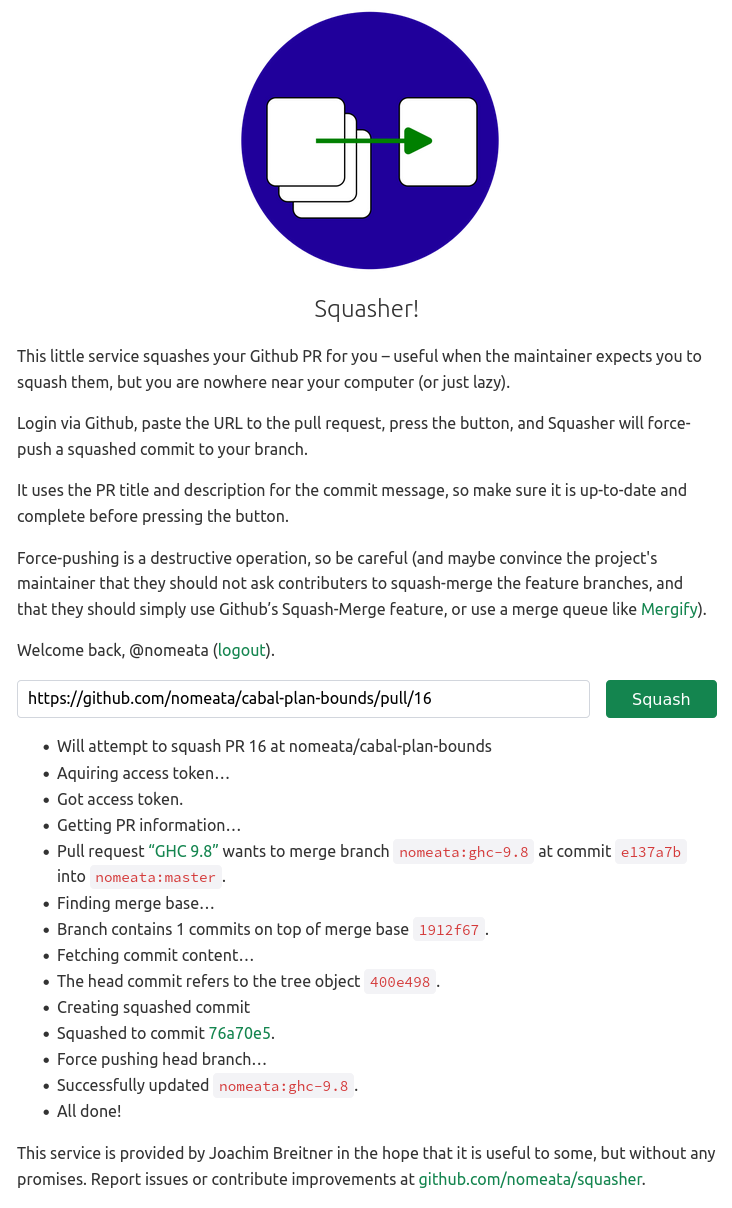 Squasher in action
Squasher in action

 Physical keyboard found.
Physical keyboard found.
